Neural Networks
Feedforward Neural Networks
A feedforward neural network is described by a directed acyclic graph, , and a weight function over the edges, . Nodes of the graph correspond to neurons. Each single neuron is modeled as a simple scalar function, . We will focus on three possible functions for : the sign function, , the threshold function, , and the sigmoid function, , which is a smooth approximation to the threshold function. We call the "activation" function of the neuron. Each edge in the graph links the output of some neuron to the input of another neuron. The input of a neuron is obtained by taking a weighted sum of the outputs of all the neurons connected to it, where the weighting is according to .
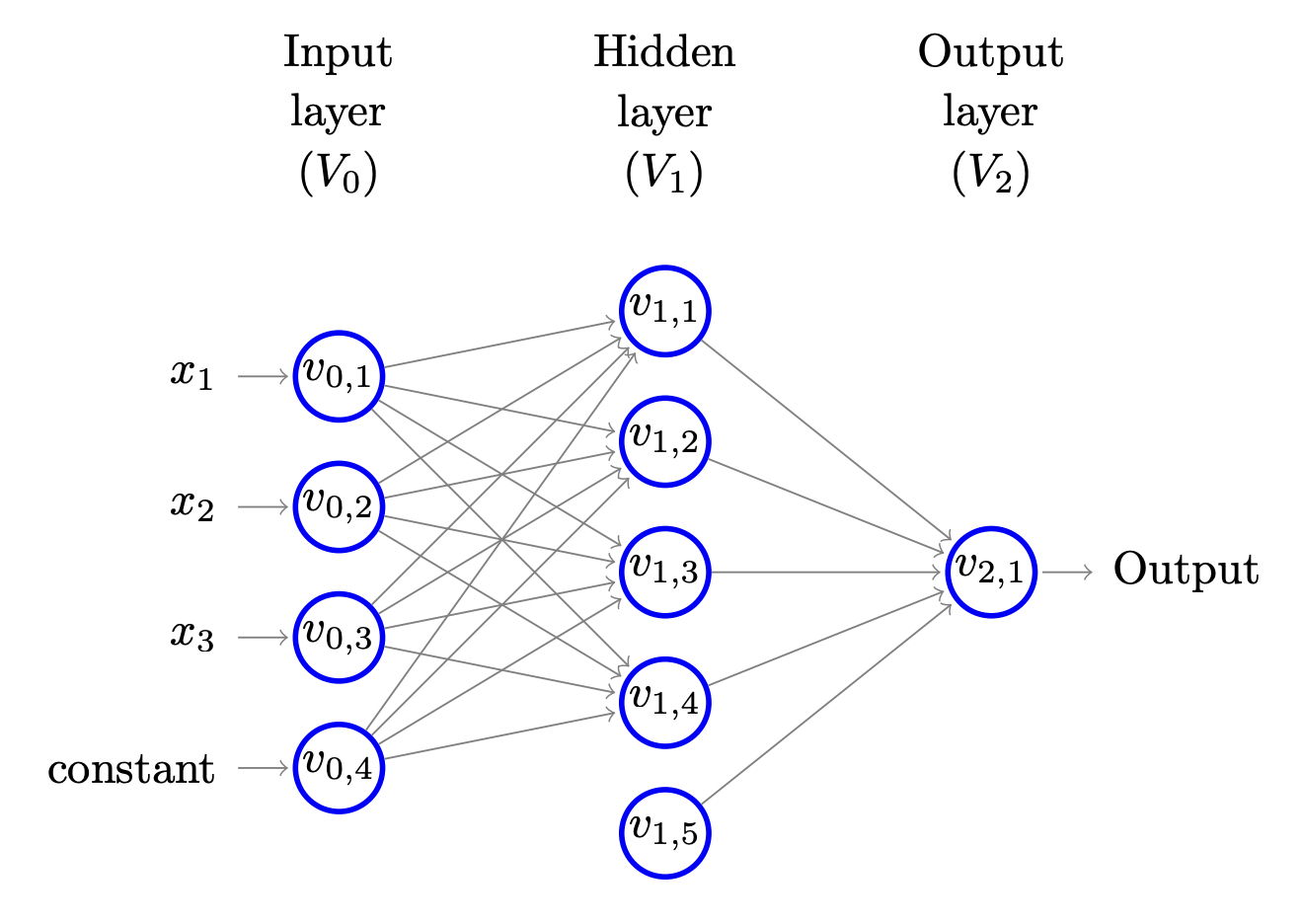
To simplify the description of the calculation performed by the network, we further assume that the network is organized in layers. That is, the set of nodes can be decomposed into a union of (nonempty) disjoint subsets, , such that every edge in connects some node in to some node in , for some . The bottom layer, , is called the input layer. It contains neurons, where is the dimensionality of the input space. For every , the output of neuron in is simply . The last neuron in is the "constant" neuron, which always outputs 1 . We denote by the th neuron of the th layer and by the output of when the network is fed with the input vector . Therefore, for we have and for we have . We now proceed with the calculation in a layer by layer manner. Suppose we have calculated the outputs of the neurons at layer . Then, we can calculate the outputs of the neurons at layer as follows. Fix some . Let denote the input to when the network is fed with the input vector . Then,
and
That is, the input to is a weighted sum of the outputs of the neurons in that are connected to , where weighting is according to , and the output of is simply the application of the activation function on its input. Layers are often called hidden layers. The top layer, , is called the output layer. In simple prediction problems the output layer contains a single neuron whose output is the output of the network.
We refer to as the number of layers in the network (excluding ), or the "depth" of the network. The size of the network is . The "width" of the network is . An illustration of a layered feedforward neural network of depth 2 , size 10 , and width 5 , is given in the following. Note that there is a neuron in the hidden layer that has no incoming edges. This neuron will output the constant .
SGD and Backpropagation

